前面講了那麼多,終於有開始要做點什麼了......
因為我也是第一次接觸網路爬蟲,查了很多文章跟一些相關書籍,發現大家最初都是搞定PTT裡的有沒有滿18歲(cookie),所以我也跟著試試看爬取這種會被擋住進入網站的東西。
我平常也沒有在爬ptt的習慣,但只要是台灣人應該多少都有聽過這個論壇吧。
今天要爬的是八卦版!
目標網址:https://www.ptt.cc/bbs/Gossiping/index.html
大家點進去應該都會先看到這個畫面吧。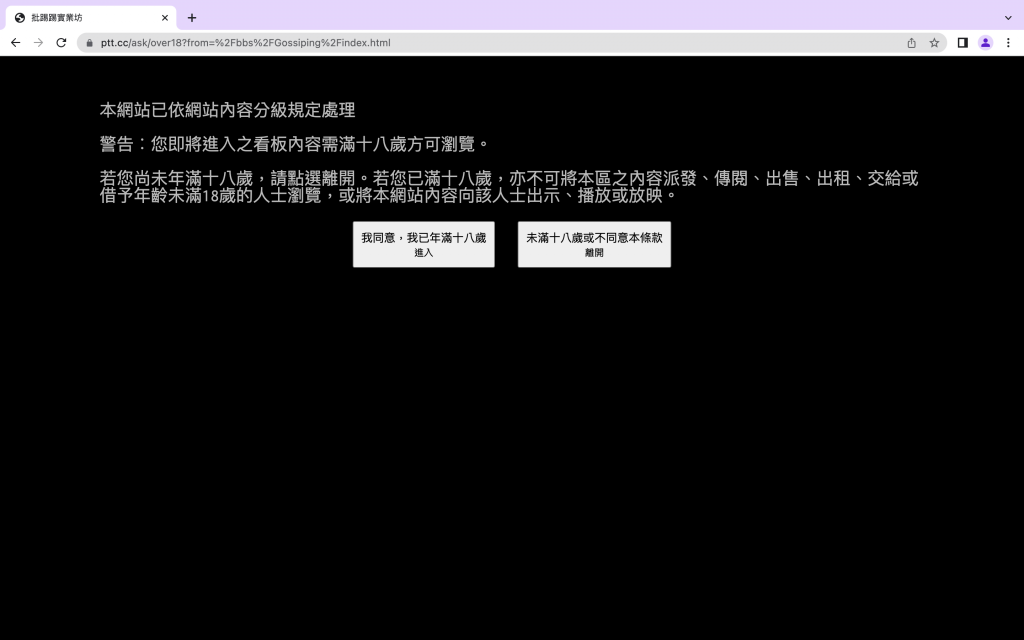
點選已滿18歲後就可以開始瀏覽論壇了。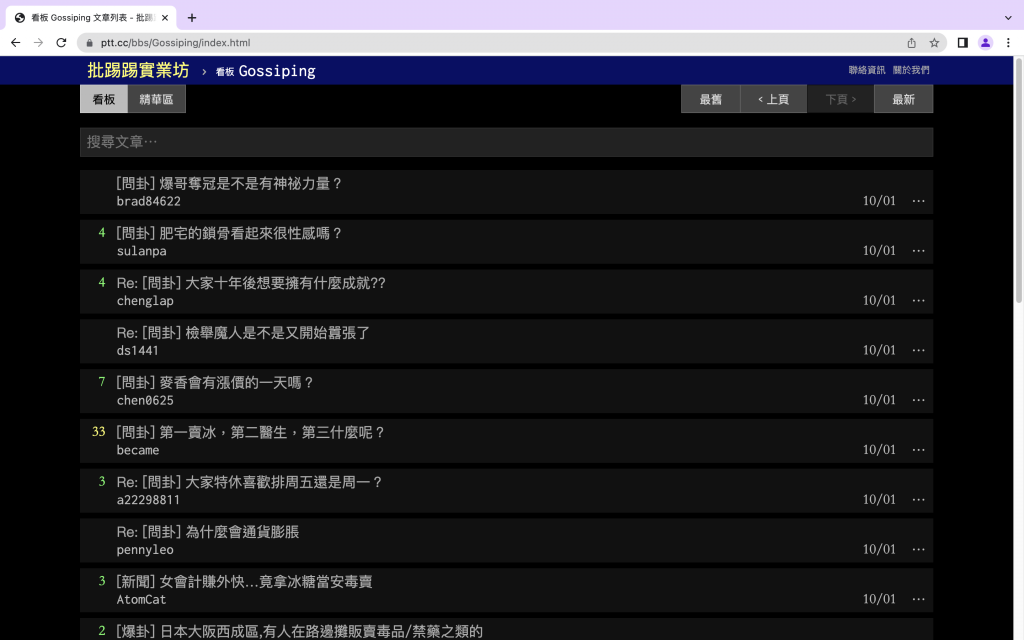
接下來我們先用GET()來看看目標網址的回應
import requests
import bs4
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
res = requests.get(url)
print(res.text)
執行之後,果不其然,回應的都是在問我有沒有滿18歲:))))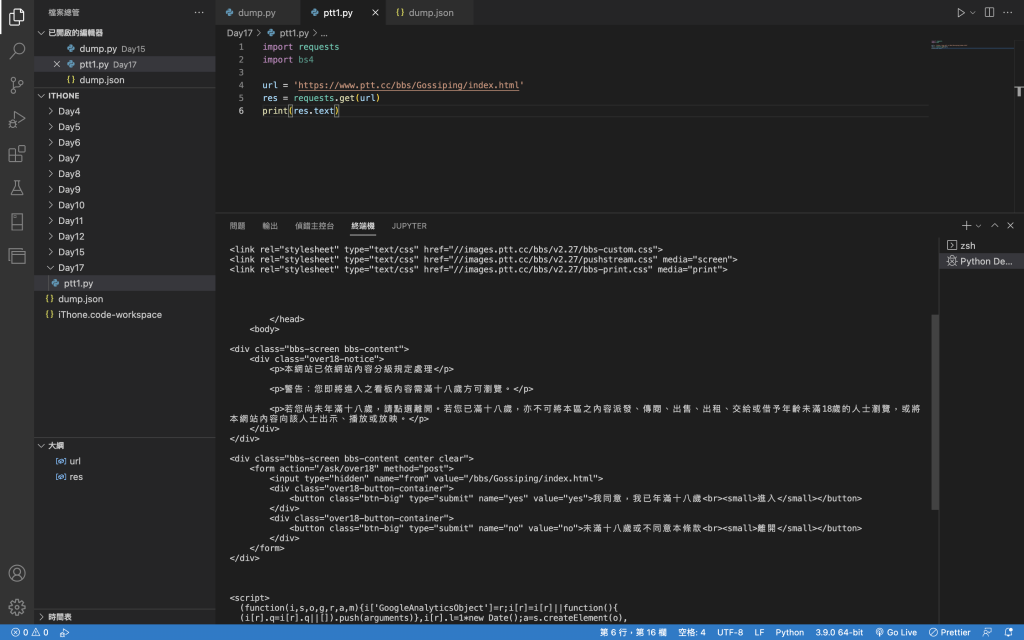
接下來我們就去找找可以繞過去的關鍵。
在Chrome裡按下f12然後command+R找到一個over18,聽起來就像是我們要找的對吧:)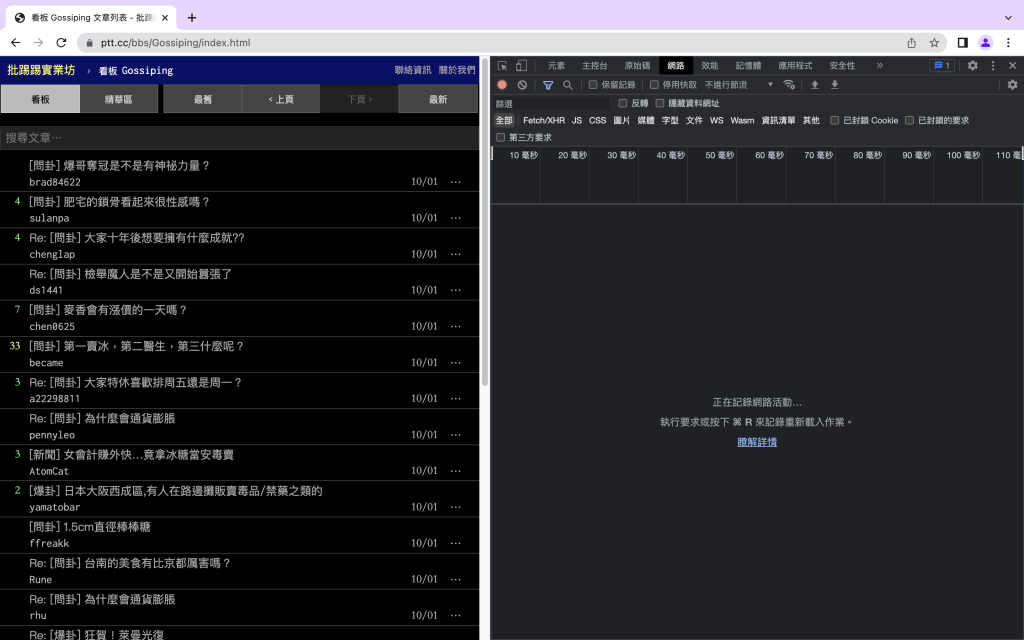
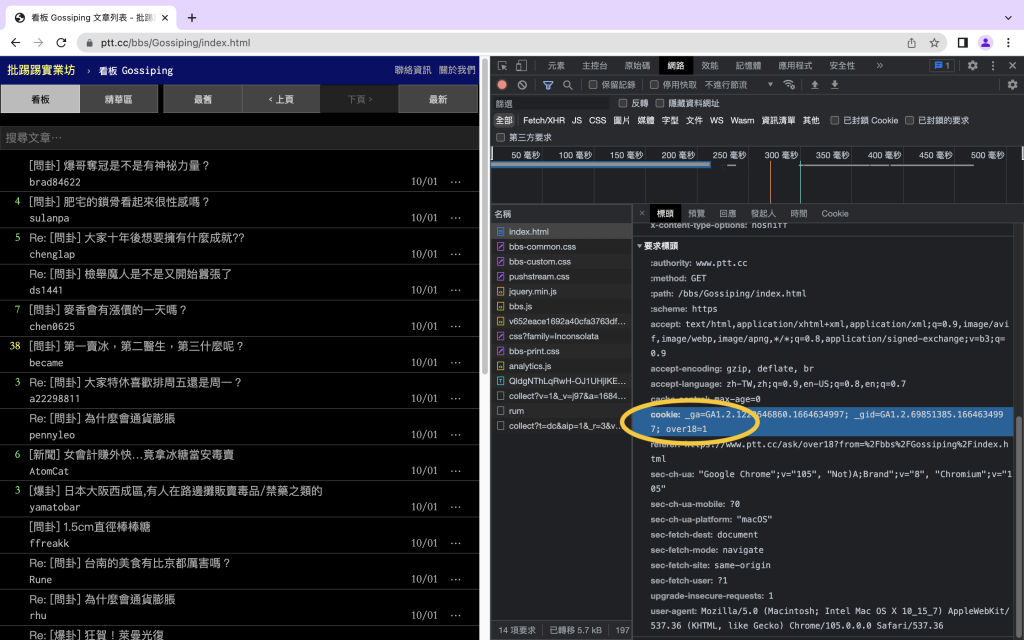
將cookies傳入之後就可以順利讀取裡面的文章了!
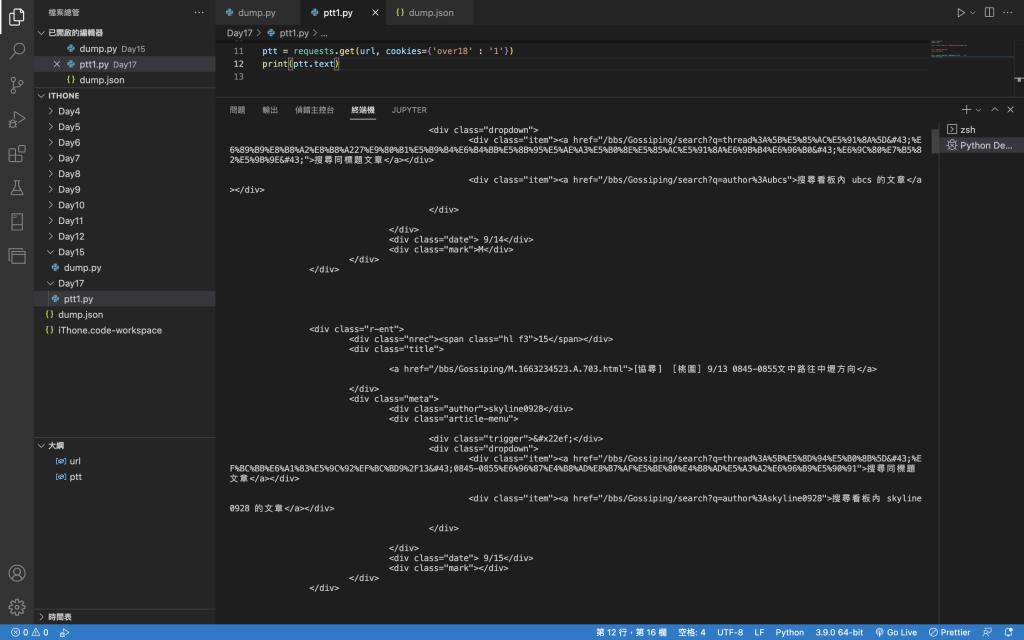
import requests
import bs4
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
ptt = requests.get(url, cookies={'over18' : '1'})
print(ptt.text)
參考書籍:
洪錦魁 -- Python網路爬蟲:大數據擷取、清洗、儲存與分析:王者歸來 2019
林俊瑋, 林修博 --- Python:網路爬蟲與資料分析入門實戰 2018

